从开始工作起,我就习惯了记录工作日志。最开始的方式非常简单,在本子上写个日期,今天是在这家公司的第多少天,顺便记录一句鼓励自己的话。
- 翻看前一天的记录确定今天是第几个工作日
- 手动找一个英语学习的网站,基本上抄个每日英语什么的,算是今天跟英语单词又说 hello 了
这是一个比较机械的活,也是我每日上班前的重要仪式,虽然有时候会因为业务比较繁忙,而忘记记录,后续我都会将空缺的那几日的工作日计算进去。
后面随着更换工作,有些公司连个本子都不发的时候,我就开始用尝试用笔记工具来记录,最后在经历了各种笔记工具的折腾之后,我开始使用 Obsidian 来记录工作日志和 TODO list。
这些重复性的操作虽然是个仪式,但是要回看前一日的计数,然后 + 1 变成今天的索引,还是挺让人烦恼的。
直到我发现了 Obsidian 的 Templater 插件,我先是是解决了自动编号的问题,后面又思考每日英语句子的获取,是不是也可以完成呢?最终在 AI 的加持下,这个脚本很快就完成了。
最终效果
现在,每次创建新的工作日志时,模板会自动生成:
#workday 2
The quieter you become, the more you can hear. 你越是安静,能听到的便越多。——拉姆·达斯
#home
<光标在这里,可以立即开始记录>
一切都是自动的:
- ✅ 工作日编号自动计算(支持归档文件夹)
- ✅ 每日英语句子自动获取(来自欧路词典)
- ✅ 光标自动定位到内容区域
- ✅ 开箱即用,无需手动操作
文件结构
我的工作日志组织方式如下:
workday/
├── template/
│ └── journal-template.md # 模板文件
├── 2024-archive/ # 归档文件夹
│ ├── 2024-01-15.md
│ ├── 2024-01-16.md
│ └── ...
├── 2025-09-01.md
├── 2025-09-02.md
└── 2025-09-24.md
每个日志都有 #workday N 标签,记录这是在当前公司工作的第几天。由于会定期归档,简单的文件计数无法满足需求,必须遍历所有子目录。
完整模板代码
<%*
// 获取英语每日一句
async function fetchDailySentence() {
try {
const url = "https://dict.eudic.net/home/dailysentence";
const response = await requestUrl({
url: url,
method: "GET",
headers: {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36"
}
});
const html = response.text;
// 辅助函数:清理 HTML 标签并返回纯文本
function stripHtml(htmlContent) {
return htmlContent
.replace(/<[^>]+>/g, '') // 移除所有 HTML 标签
.replace(/&#x([0-9a-fA-F]+);/g, (_, hex) => String.fromCharCode(parseInt(hex, 16))) // 十六进制实体 ' → '
.replace(/&#(\d+);/g, (_, dec) => String.fromCharCode(parseInt(dec, 10))) // 十进制实体 ' → '
.replace(/ /g, ' ')
.replace(/&/g, '&')
.replace(/</g, '<')
.replace(/>/g, '>')
.replace(/"/g, '"')
.replace(/'/g, "'")
.replace(/’/g, '\u2019') // 右单引号 '
.replace(/‘/g, '\u2018') // 左单引号 '
.replace(/”/g, '\u201D') // 右双引号 "
.replace(/“/g, '\u201C') // 左双引号 "
.replace(/—/g, '\u2014') // 破折号 —
.replace(/–/g, '\u2013') // 短破折号 –
.replace(/…/g, '\u2026') // 省略号 …
.trim();
}
// 提取英文句子 - 查找包含英文文本的 p 标签
let english = "";
const englishMatch = html.match(/<p[^>]*class="[^"]*[^c][^o][^n][^t][^e][^n][^t][^"]*"[^>]*>(.*?)<\/p>/is);
if (englishMatch) {
const text = stripHtml(englishMatch[1]);
// 只保留纯英文内容(排除纯中文)
if (/[a-zA-Z]/.test(text) && text.split('').filter(c => /[a-zA-Z]/.test(c)).length > text.split('').filter(c => /[\u4e00-\u9fa5]/.test(c)).length) {
english = text;
}
}
// 如果上面没有找到,尝试其他可能的类名
if (!english) {
const altMatch = html.match(/<p[^>]*>([A-Za-z][^<]+)<\/p>/);
if (altMatch) {
english = stripHtml(altMatch[1]);
}
}
// 提取中文翻译
let chinese = "";
const chineseMatch = html.match(/<p[^>]*class="[^"]*sect-trans[^"]*"[^>]*>(.*?)<\/p>/is);
if (chineseMatch) {
chinese = stripHtml(chineseMatch[1]);
}
// 如果上面没找到,尝试查找包含中文的 p 标签
if (!chinese) {
const cnMatches = html.match(/<p[^>]*>([\s\S]*?)<\/p>/g) || [];
for (const match of cnMatches) {
const text = stripHtml(match);
// 查找包含中文且长度合理的文本
if (/[\u4e00-\u9fa5]/.test(text) && text.length > 10 && text.length < 100 && !text.includes('每日') && !text.includes('出自')) {
chinese = text;
break;
}
}
}
// 提取作者
let author = "";
const authorMatch = html.match(/本句出自[::]\s*([^(<\n]+)/);
if (authorMatch) {
author = stripHtml(authorMatch[1]).trim();
}
// 如果没有找到作者,尝试其他格式
if (!author) {
const altAuthorMatch = html.match(/———\s*([^<\n]+)/);
if (altAuthorMatch) {
author = stripHtml(altAuthorMatch[1]).trim();
}
}
return { english, chinese, author };
} catch (error) {
console.error("获取每日一句失败:", error);
return { english: "", chinese: "", author: "" };
}
}
const dailySentence = await fetchDailySentence();
console.log(dailySentence);
// 简单粗暴的方法
const workdayFiles = app.vault.getMarkdownFiles().filter(file => {
// console.log("检查文件:", file.path);
return file.path.startsWith("workday/") &&
!file.path.toLowerCase().includes("template");
});
/*console.log("符合条件的文件:");
workdayFiles.forEach((file, index) => {
console.log(`${index + 1}: ${file.path}`);
});*/
let dayCount = workdayFiles.length;
console.log("计算出的天数:", dayCount);
_%>
#workday <% dayCount %>
<% dailySentence.english %> <% dailySentence.chinese %>
<%* if (dailySentence.author) { _%>——— <% dailySentence.author %>
<%* } _%>
#home
<% tp.file.cursor() %>
功能详解
1. 自动工作日编号
核心逻辑:
const workdayFiles = app.vault.getMarkdownFiles().filter(file => {
return file.path.startsWith("workday/") &&
!file.path.toLowerCase().includes("template");
});
let dayCount = workdayFiles.length;
特点:
- 📁 递归扫描
workday文件夹及所有子目录 - 🚫 自动排除模板文件(名称包含 “template”)
- 📊 只统计
.md文件,忽略其他格式 - ✅ 支持任意层级的归档文件夹
2. 每日英语句子
数据来源:欧路词典每日一句
注意事项:仅供学习使用,不要用于其他途径。
获取内容:
- 英文原句
- 中文翻译
- 句子出处/作者(如果有)
实现细节:
- 使用 Obsidian 的
requestUrlAPI 获取网页内容 - 通过正则表达式提取句子和翻译
- 包含备用匹配方案,提高成功率
- 异步获取,不阻塞模板执行
3. 智能光标定位
使用 <% tp.file.cursor() %> 在内容生成完成后自动将光标定位到正文区域,可以立即开始记录当天的工作内容。
配置步骤
步骤 1:安装插件
在 Obsidian 设置中安装 Templater 插件并启用。
步骤 2:启用必要功能
在 Templater 设置中确保以下选项已启用:
- Automatic jump to cursor:模板执行后自动跳转到光标位置
- Trigger Templater on new file creation:支持文件创建时自动应用模板
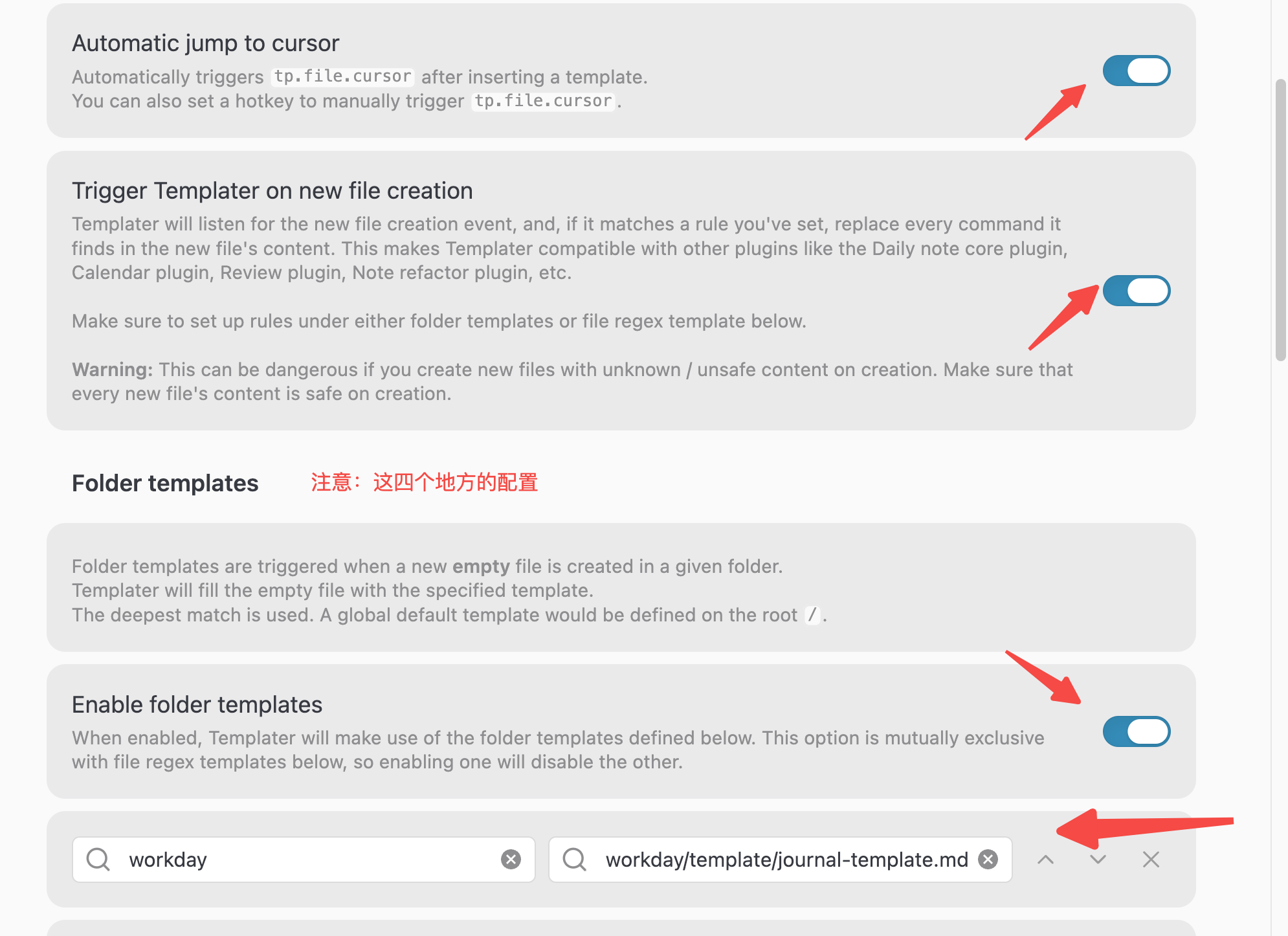
步骤 3:创建模板文件
在模板文件夹中创建 journal-template.md,将上述完整代码粘贴进去。
步骤 4:配置文件夹模板(可选)
如果希望在 workday 文件夹中创建的所有新文件都自动应用此模板:
请一定注意我将 journal 的默认路径调整到了我创建的 workday 目录,如果你更加倾向于其他路径,请根据实际情况调整配置。
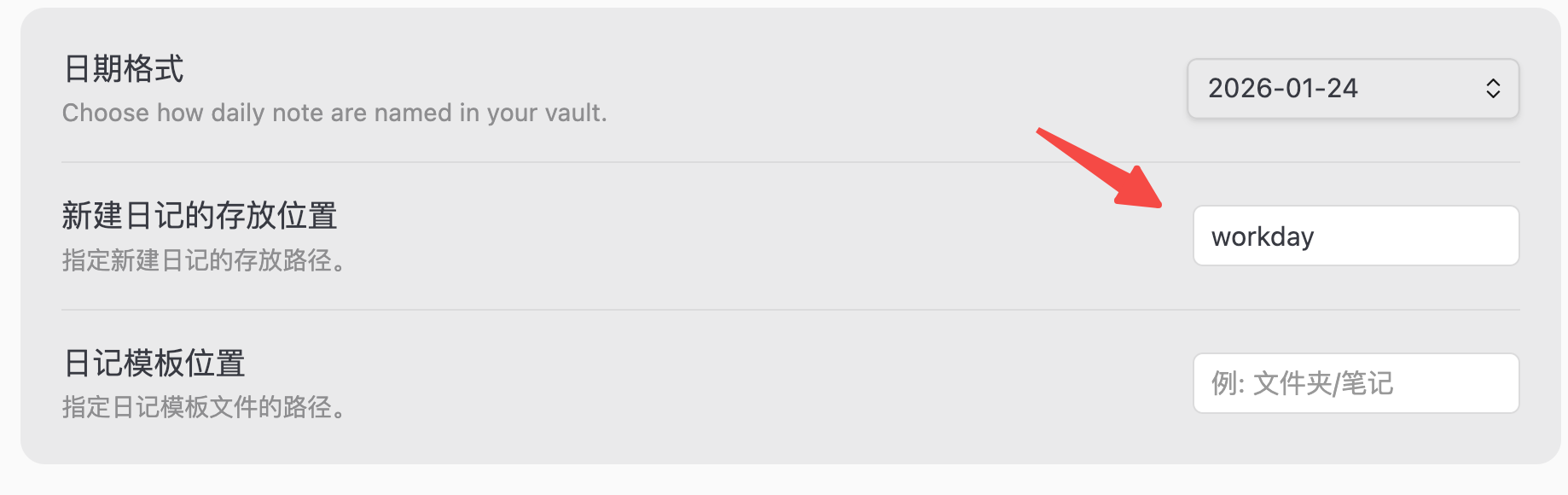
- 进入 Templater 设置 → Folder Templates
- 添加规则:
workday文件夹 →journal-template.md
使用体验
创建前
需要做的事情:
1. 打开前一天的日志
2. 查看是第几个工作日
3. 手动输入编号
4. 找一句励志的话
5. 开始写内容
创建后
需要做的事情:
1. 创建新文件(甚至可以设置快捷键)
2. 直接开始写内容 ✅
所有繁琐的准备工作都由模板自动完成!
调试技巧
如果遇到问题,可以打开开发者控制台(Ctrl/Cmd + Shift + I)查看调试信息:
console.log("计算出的天数:", dayCount);
console.log("获取到的句子:", dailySentence);
控制台会显示:
- 统计到的工作日数量
- 获取到的英语句子内容
- 任何可能的错误信息
扩展思路
这个模板框架非常灵活,可以根据需求扩展更多功能:
1. 添加天气信息
async function fetchWeather() {
// 调用天气 API
}
2. 添加每日任务
const tasks = [
"- [ ] 查看邮件",
"- [ ] 站立会议",
"- [ ] 代码审查"
].join("\n");
3. 添加历史上的今天
const today = tp.date.now("MM-DD");
// 查询历史事件
4. 自定义标签和分类
const tags = ["#工作", "#学习", "#总结"];
其他应用场景
这个方案不仅适用于工作日志,还可以用于:
- 学习日志:记录学习的第几天 + 每日学习格言
- 健身日志:统计锻炼天数 + 健身励志语
- 项目日志:跟踪项目进展 + 项目管理名言
- 读书笔记:记录阅读进度 + 每日书摘
只需调整文件夹路径、标签名称和数据源即可。
总结
通过 Templater 的强大功能,我们将原本需要手动完成的重复性工作自动化,让工具真正为我们服务。这个小小的改进带来的好处:
- 节省时间:每天至少节省 1-2 分钟的准备时间
- 提升专注:创建后立即可以开始记录,不被琐事打断
- 增添乐趣:每天都有新的英语句子,增加学习动力
- 准确可靠:自动计算编号,不会出错
更重要的是,这种自动化思维可以应用到知识管理的各个方面。当我们学会用代码解决重复性问题时,Obsidian 就不仅仅是一个笔记软件,而是一个真正的生产力工具。
如果你也想让日志记录更加高效和有趣,不妨试试这个方案。相信你会和我一样,享受自动化带来的便利和愉悦!
附录:常见问题
Q: 网络请求失败怎么办?
A: 模板已经包含了错误处理,如果获取失败会返回空字符串,不影响日志创建。可以稍后手动添加内容。
Q: 可以更换其他英语句子来源吗?
A: 当然可以!只需修改 fetchDailySentence 函数中的 URL 和解析逻辑即可。
Q: 归档文件夹的名称有要求吗?
A: 没有要求,当前的示例是在 workday/ 目录下,如果你要修改成 journals,请将 templater 中的 Folder template 设置正确即可,不包含 “template” 即可被统计。
Q: 光标没有自动定位怎么办?
A: 确保在 Templater 设置中启用了 “Automatic jump to cursor” 选项。
希望这个模板能帮助你建立更好的工作习惯,让每一天的记录都充满仪式感!